Faster String Work with Span (and Friends)
If your app spends real time poking at strings — parsing logs, trimming tokens, slicing CSVs — allocations are usually the hidden tax. Span<char> and ReadOnlySpan<char> let you look at pieces of text without allocating new strings. That means less GC pressure, fewer cache misses, and happier perf charts.
Below are patterns I use a lot, followed by a ready-to-run BenchmarkDotNet class so you can measure the gains on your own machine.
TL;DR — When to Reach for Span
- You’re doing repeated
Substring,Split, or regex for simple delimiters. - You need to scan/search inside a string (e.g., find the Nth
;). - You can build the final output once using
string.Createrather than multiple intermediate strings. - You want to parse numbers or dates directly from a slice.
1. Stop Substring-ing
Before
static string GetValue_Substring(string input, string key)
{
var target = key + "=";
var start = input.IndexOf(target, StringComparison.Ordinal);
if (start < 0) return null;
start += target.Length;
var end = input.IndexOf(';', start);
if (end < 0) end = input.Length;
return input.Substring(start, end - start); // allocates
}After
static ReadOnlySpan<char> GetValue_Span(ReadOnlySpan<char> input, ReadOnlySpan<char> key)
{
var target = key;
var eqIdx = input.IndexOf('=');
while (eqIdx >= 0)
{
var k = input[..eqIdx].Trim();
var rest = input[(eqIdx + 1)..];
var semi = rest.IndexOf(';');
var val = semi >= 0 ? rest[..semi] : rest;
if (k.SequenceEqual(target)) return val;
var nextSemi = input.IndexOf(';');
if (nextSemi < 0) break;
input = input[(nextSemi + 1)..];
eqIdx = input.IndexOf('=');
}
return ReadOnlySpan<char>.Empty;
}Convert to a string only when needed:
var val = GetValue_Span(line.AsSpan(), "role".AsSpan());
var role = val.IsEmpty ? null : new string(val);2. Parse Numbers Straight from a Slice
Before
static int SumCsv_Substring(string csv)
{
var sum = 0;
foreach (var part in csv.Split(',')) // alloc per segment + array
sum += int.Parse(part);
return sum;
}After
static int SumCsv_Span(ReadOnlySpan<char> csv)
{
var sum = 0;
while (!csv.IsEmpty)
{
var i = csv.IndexOf(',');
var token = i >= 0 ? csv[..i] : csv;
if (int.TryParse(token, out var n)) sum += n;
if (i < 0) break;
csv = csv[(i + 1)..];
}
return sum;
}No Split, no per-token strings, less GC churn.
3. Build the Final String Once with string.Create
static string JoinWithDash_Span(ReadOnlySpan<char> a, ReadOnlySpan<char> b)
{
var len = a.Length + 1 + b.Length;
return string.Create(len, (a, b), static (dest, state) =>
{
state.a.CopyTo(dest);
dest[state.a.Length] = '-';
state.b.CopyTo(dest[(state.a.Length + 1)..]);
});
}That’s one allocation — the final string.
4. Fast Searching: IndexOfAny
static int CountTokens_Span(ReadOnlySpan<char> s)
{
int count = 0, i = 0;
while (i < s.Length)
{
while (i < s.Length && " \t\n\r,;".Contains(s[i])) i++;
if (i >= s.Length) break;
count++;
while (i < s.Length && !" \t\n\r,;".Contains(s[i])) i++;
}
return count;
}5. Stack Buffers for Small Transforms
static string ToUpperAscii_Small(ReadOnlySpan<char> input)
{
if (input.Length > 256)
return input.ToString().ToUpperInvariant();
Span<char> buf = stackalloc char[input.Length];
for (int i = 0; i < input.Length; i++)
buf[i] = (char)(input[i] is >= 'a' and <= 'z' ? input[i] - 32 : input[i]);
return new string(buf);
}Pitfalls & Sanity Checks
- Lifetimes matter — spans are stack-only. Don’t store them in fields.
- Keep
stackallocsmall — under a few KB is fine. - Measure first — sometimes
Substringis “fast enough.”
Benchmarks (Plug & Run)
You can benchmark all these patterns using BenchmarkDotNet.
Create a new project:
dotnet new console -n SpanStringBench
cd SpanStringBench
dotnet add package BenchmarkDotNetReplace Program.cs with:
using BenchmarkDotNet.Running;
BenchmarkRunner.Run<StringSpanBenchmarks>();Then add the benchmark class:
using System;
using System.Globalization;
using BenchmarkDotNet.Attributes;
using BenchmarkDotNet.Configs;
using BenchmarkDotNet.Diagnosers;
[MemoryDiagnoser]
[GroupBenchmarksBy(BenchmarkLogicalGroupRule.ByCategory)]
[CategoriesColumn]
public class StringSpanBenchmarks
{
private string _csv = "12,34,56,78,90,123,456,789,1000,2000,3000";
[Benchmark(Baseline = true, Description = "Split+Parse CSV")]
[BenchmarkCategory("Parse")]
public int SumCsv_Split()
{
var sum = 0;
foreach (var part in _csv.Split(',')) sum += int.Parse(part, CultureInfo.InvariantCulture);
return sum;
}
[Benchmark(Description = "Span CSV parsing")]
[BenchmarkCategory("Parse")]
public int SumCsv_Span()
{
var csv = _csv.AsSpan();
var sum = 0;
while (!csv.IsEmpty)
{
var i = csv.IndexOf(',');
var token = i >= 0 ? csv[..i] : csv;
if (int.TryParse(token, NumberStyles.Integer, CultureInfo.InvariantCulture, out var n))
sum += n;
if (i < 0) break;
csv = csv[(i + 1)..];
}
return sum;
}
}Run it:
dotnet run -c ReleaseAs you can see, this are the results on my computer:
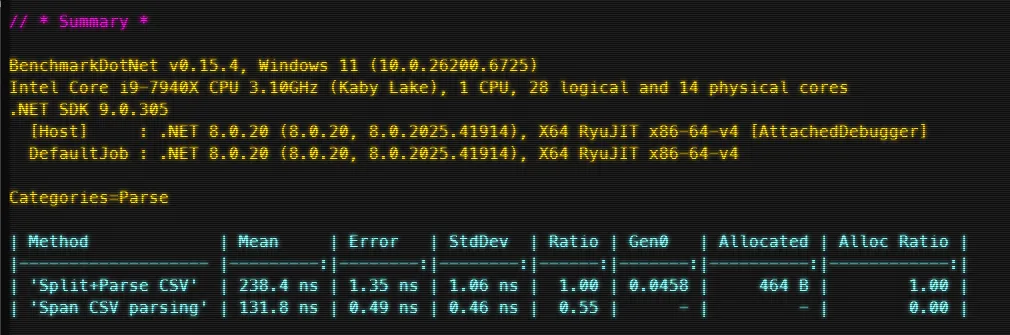
- Performance gain: The span-based implementation is roughly 1.8× faster (238 → 132 ns). That’s a meaningful speedup, especially in tight loops or high-throughput parsing scenarios.
- Zero allocations:
The Split version allocates memory for an array and substrings every call (464 bytes).
The Span
version does no heap allocations at all — all work stays on the stack, drastically reducing GC pressure. - GC impact: The traditional version triggers minor Gen0 collections over time; the span version completely avoids this, keeping latency more predictable.
🧠 Bonus Point 6 — Streaming with ReadOnlySequence
If your input comes in chunks (e.g., sockets, pipelines, or file reads), ReadOnlySequence<char> represents many buffers as one logical sequence.
Use SequenceReader<char> to scan across segment boundaries — it’s like Span<char> for streaming data.
Example: Summing CSV Across Segments
using System;
using System.Buffers;
static int SumCsv_ROS(in ReadOnlySequence<char> seq)
{
var reader = new SequenceReader<char>(seq);
var sum = 0;
while (!reader.End)
{
if (reader.TryReadTo(out ReadOnlySequence<char> token, ',', advancePastDelimiter: true))
{
if (TryParseInt(token, out var n)) sum += n;
}
else
{
var remaining = reader.UnreadSequence;
if (TryParseInt(remaining, out var last)) sum += last;
reader.Advance(remaining.Length);
}
}
return sum;
}
// Helper that parses int across segments safely
static bool TryParseInt(in ReadOnlySequence<char> seq, out int value)
{
if (seq.IsSingleSegment)
return int.TryParse(seq.FirstSpan, out value);
var len = (int)seq.Length;
Span<char> buf = stackalloc char[Math.Min(len, 256)];
var written = 0;
foreach (var mem in seq)
{
var span = mem.Span;
span.CopyTo(buf.Slice(written));
written += span.Length;
}
return int.TryParse(buf.Slice(0, written), out value);
}Why It Matters
- Works seamlessly with
System.IO.Pipelines. - No
Split, no copying large buffers. - Efficient for streaming or framed protocols (e.g., CSV logs over TCP).
When to Use
- You’re parsing data that arrives in chunks (network/file).
- You want to avoid copying into one big string.
- You still want Span-like low-allocation parsing.
Summary:
Span<T> and ReadOnlySequence<T> are your go-to tools for faster, allocation-light string and text processing in C#.
Start small — refactor hot loops, measure, and watch your GC pauses shrink.

Resistance is futile.