
The new Concurrent Collections
In a world where processes are no longer sequential but parallel, we’re increasingly likely to run into concurrency issues when accessing shared resources. Conceptually speaking, this is something developers are already used to when working with database managers like Oracle or SQL Server, since multiple users can access or modify the same information.
However, most developers have rarely had to deal with locks on in-memory collections, since not everyone creates applications where multiple threads access shared resources. In fact, if you’ve ever had to do this, you know perfectly well that before TPL appeared, it was one of the most complex disciplines in software development - almost as hard as naming things properly (*). It’s something that promotes baldness, and trust me, I speak from experience :)
(*) There are only two hard things in Computer Science: cache invalidation and naming things.
However, since TPL appeared in .NET Framework 4.0, it’s much easier to develop applications that execute processes in parallel or asynchronously. But this means we sometimes forget that there are multiple threads running at the same time, and this could lead to unwanted effects when accessing shared resources, like an in-memory collection of elements.
For example: let’s say we have a scenario where we have a list of customers in memory and a couple of tasks that access that collection. The first task might be checking if all customers meet condition X, and if they don’t, removing the customer from the collection. Meanwhile, the second task might be updating some customer property, like age.
A real scenario
Does this scenario pose any danger? At first glance, we might think not. It’s enough for the second task to verify if the customer exists in the collection before updating it. Sure? Well, no. At least not if the collection we’re using isn’t one of the new ones defined within the System.Collections.Concurrent namespace. And to see this better, let’s make a small example with code, which is what we all like.
Step 1 - Define a Customer Class
public class Customer
{
public int CustomerId { get; set; }
public string Name { get; set; }
public int Age { get; set; }
public static List<Customer> GetSampleCustomers(int n)
{
Random r = new Random(Guid.NewGuid().GetHashCode());
List<Customer> customers = new List<Customer>();
for (int i = 0; i < n; i++)
{
customers.Add(new Customer()
{
CustomerId = i,
Name = string.Format("Customer {0}", i),
Age = r.Next(20, 80)
});
}
return customers;
}
}Step 2 - Create a Dictionary
Dictionary<int, Customer> dic1 = new Dictionary<int,Customer>();Step 3 - Create 100,000 sample customers
dic1 = Customer.GetSampleCustomers(100000).ToDictionary(p => p.CustomerId);Step 4 - Define 2 methods that compete with each other
Now, let’s complicate the example a bit more and create two methods that simulate deleting and updating the objects contained in the collection. Then we’ll call these methods for 100 random objects in parallel to see what effects occur.
private void DeleteItem1(int id)
{
if (dic1.ContainsKey(id) && dic1[id].Age < 30) dic1.Remove(id);
}
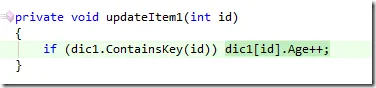
private void UpdateItem1(int id)
{
if (dic1.ContainsKey(id)) dic1[id].Age++;
}
private void button1_Click(object sender, EventArgs e)
{
for (int i = 0; i < 100; i++)
{
Random r = new Random(Guid.NewGuid().GetHashCode());
int id = r.Next(1, dic1.Count);
Task.Factory.StartNew(() => DeleteItem1(id));
Task.Factory.StartNew(() => UpdateItem1(id));
}
}Step 5 - Let’s play :)
We run our application and if a collision occurs, we might get a nice error like this, where basically it tries to access an element in the collection that no longer exists (If it doesn’t happen the first time, repeat the test until you see it).
And I say it might happen, but it’s not guaranteed. We might have to repeat the process several times, because in an environment where multiple threads access a shared resource, nothing guarantees the error will occur. Sometimes it happens the first time and sometimes the fourth, but keep in mind that when it’s in production, it will always happen on Friday afternoon five minutes before the weekend starts ;)
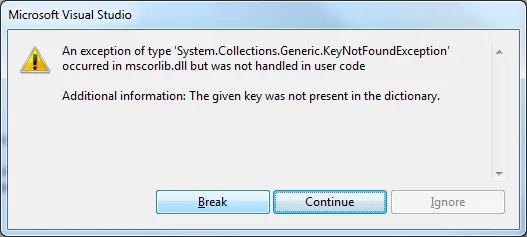
Specifically on the line that increments the customer’s age:
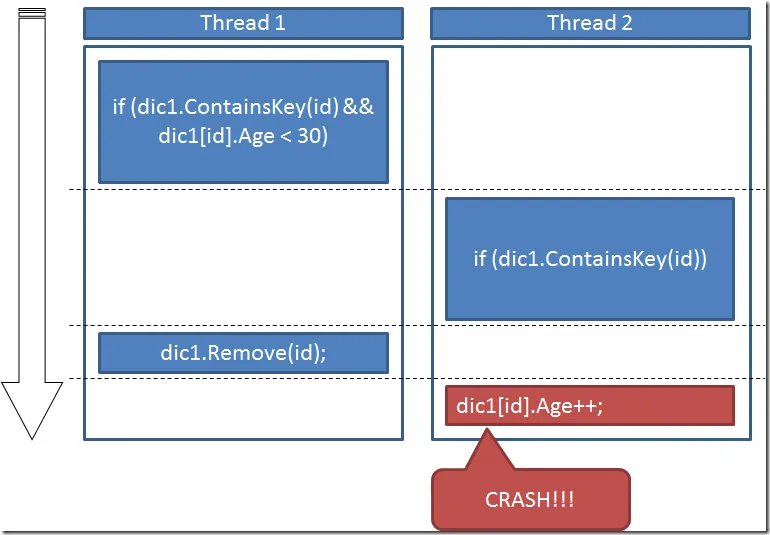
Let’s analyze why the error occurs: how is it possible that it doesn’t find the element in the collection if we precisely verified its existence in the previous line? Well, there’s the catch - we verified it in the previous line. To us - poor developers - it seems like the previous line where we verify if it exists and the next line where we delete it go one after the other, but really in an asynchronous environment there’s a whole world between both. And that’s because both lines execute separately, without any kind of locking, there’s no Transactionality like in databases. So while the first thread verifies that element exists in the collection and deletes it, the second thread arrives and… WHAM! It deletes it.
The new ConcurrentDictionary class
To deal with these cases, a new set of collections specialized for multithreading environments come into play. One of the most popular is a variation of the classic Dictionary: the ConcurrentDictionary. This class provides a series of alternative methods for adding, modifying, or removing elements called TryAdd, TryUpdate, or TryRemove. The advantage of these methods is that they’re transactional and provide Atomicity. That is, they guarantee that if invoked, they execute completely: Either the element is added/modified/removed from the collection or False is returned because the operation couldn’t be performed. It also provides a TryGetValue method that attempts to get an element from the collection. All these methods implement locks internally to ensure no one else accesses the element while the requested operation is being performed.
Fixing the previous example :)
Let’s modify the previous example using this new collection to observe its behavior in the previous environment.
Step 1 - Change Dictionary to ConcurrentDictionary
ConcurrentDictionary<int, Customer> dic2 =
new ConcurrentDictionary<int, Customer>();Step 2 - Create 100,000 sample customers
Just like we did before. Here we can see the first difference, since we use one of the new TryXXX methods:
Customer.GetSampleCustomers(100000).ForEach(c => dic2.TryAdd(c.CustomerId, c));Step 3 - Modify the 2 competing methods
private void DeleteItem2(int id)
{
Customer c;
if(!dic2.TryRemove(id, out c)) Console.WriteLine("Error deleting!");
}
private void UpdateItem2(int id)
{
Customer c;
if (!dic2.TryGetValue(id, out c))
{
Console.WriteLine("Error getting value");
}
else
{
Customer newc = new Customer() {
CustomerId = c.CustomerId, Name = c.Name, Age = c.Age };
newc.Age++;
if (!dic2.TryUpdate(id, newc, c)) Console.WriteLine("Error updating!");
}
}In deletion, we use the TryRemove method which needs the id of the element to delete, and if it successfully deletes it, returns True and the deleted object in the method’s second out parameter. If it doesn’t delete it, it returns False and the default value of the object to delete in the second parameter.
The update is a bit more complex, since we must first ensure that the element to modify exists in the collection using the TryGetValue method, which basically works the same as the previous TryDelete method. Once we’ve verified that object exists in the collection, we create a replica of the customer, modify its age, and call the TryUpdate method, which handles the modification.
It’s interesting to note that for the modification to be performed correctly, we must provide the object’s key in the collection, the new value of the object (in this case the customer replica whose age we’ve modified), and a third parameter which is the original value of the object, used for comparison.
Step 4 - Let’s play again :D
We run it and if we go to the console window we can observe the result:
Error getting value
Error getting value
Error getting value
Error getting value
Error updating!
Error getting value
Error getting value
Error getting valueIn most cases, we get a read error because the element has already been removed from the collection, but in some cases the error will occur in the TryUpdate method. This means the TryGetValue call finds the element, but when we go to modify it, it no longer exists in the collection. Perfect! :)
Conclusion
The advantage of using specific collections in multithreading environments is clear: They guarantee that access to shared resources is transactional, in the purest database style. Granted, their programming is a bit more complex, but it’s nothing like what had to be done in the old days when TPL didn’t exist.
On the other hand, these collections should only be used in cases where shared resources are accessed, because otherwise we’re complicating our code and a ConcurrentDictionary isn’t as efficient as a Dictionary, especially in environments that are more write-heavy than read-heavy.
I hope to find time for another post explaining other collections in this namespace, like ‘BlockingCollection’ or ‘ConcurrentBag’, which are more specialized collections. The first is optimized for scenarios where the same thread produces and consumes objects, while the second has been specially designed for producer-consumer scenarios.

Resistance is futile.